外观
开源LLM模型及社区项目调研
注意:
该博客内容不对真实性、专业性作出任何保障,仅作记录参考使用,如有错误欢迎联系指正
本调研内容截止日期为 2023 年 7 月 28 日,由于 LLM 的强时效性,您在进行参考时务必确认相关内容是否接近此日期及此日期之后的更新或修改
引言
近年来,大型语言模型(Large Language Model,LLM)取得了显著的进展。
其中,GPT-4 作为代表性的语言模型,在文本生成、问答系统和对话生成方面表现出色。然而,由于特定场景对隐私性和准确性的要求,需要寻找一种能够在本地部署大型语言模型并能提供准确回答的解决方案。
具体到本次调研,简单列出需求如下:
在 24G 显存条件下可以完成项目部署;
可部署的模型对中文有一定支持;
项目提供给用户的答案应当是足够可靠的;
项目要便于部署、维护,有一定的社区生态支持。
LLM 规模与 GPU 需求
通常,大型语言模型(Large Language Model,LLM)的规模会在模型名称中使用类似于7B的关键词,用来表示该模型的参数规模为 70 亿。一般性地,模型参数越多,模型效果越好,对硬件的需求也越高。
在 LLM 的部署过程中,可以采用模型量化技术对模型参数进行压缩,以降低硬件需求、提升计算速度。常见的量化等级包括FP16、BF16、INT8和INT4,分别代表使用 16 位浮点数、16 位浮点数(Google Brain Floating)、8 位整数和 4 位整数进行近似计算。据不可靠来源,对模型进行量化可能会使模型更容易出现幻觉,因此本次部署中在相似条件下优先选择FP16、BF16精度进行部署。
以ChatGLM2-6B为例,在不同的量化等级下所需的最小显存如下:
| 量化等级 | 编码 2048 长度的最小显存 | 生成 8192 长度的最小显存 |
|---|---|---|
| FP16 / BF16 | 13.1 GB | 12.8 GB |
| INT8 | 8.2 GB | 8.1 GB |
| INT4 | 5.5 GB | 5.1 GB |
一般而言,7B规模的模型以INT4量化需要 5G 显存,在此基础上参数规模每提高倍,需要的显存大小变为。如果以 16 位浮点数精度部署模型,24G 显存能运行的最大模型为 14B 左右。
量化对模型性能的影响
GLM 团队也测试了量化对模型性能的影响。结果表明,量化对模型性能的影响在可接受范围内。
| ChatGLM-6B 量化等级 | Accuracy (MMLU) | Accuracy (C-Eval dev) |
|---|---|---|
| BF16 | 45.47 | 53.57 |
| INT4 | 43.13 | 50.30 |
模型选取
在模型选取阶段,我们参考了一些国内外各模型测评方案、LLM 跟踪榜单,主要包括以下内容:
- 评测集
MMLU:一个包含 57 个多选任务的英文评测数据集,涵盖了初等数学、美国历史、计算机科学、法律等,难度覆盖高中水平到专家水平,在Hugging Face上提供了Open LLM Leaderboard测试信息统计。
C-Eval:一个全面的中文基础模型评估套件,涵盖了 52 个不同学科的 13948 个多项选择题,在官网提供了C-Eval 排行榜。
Gaokao:由复旦大学研究团队构建的基于中国高考题目的综合性考试评测集,包含多科目多题型,并提供了 9 种模型的评测结果。
AGIEval:用于评估基础模型在与人类认知和解决问题相关的任务中的一般能力,基于普通大学入学考试、数学竞赛、律师资格考试等 20 项面向普通考生的官方、公开、高标准的入学和资格考试构建。
CMMLU:一个综合性的中文评估基准,专门用于评估语言模型在中文语境下的知识和推理能力,涵盖了从基础学科到高级专业水平的 67 个主题,提供了 14 种 LLM 的评测结果。
PromptCBLUE:将 16 种不同的医疗场景 NLP 任务转化为基于提示的语言生成任务形成的首个中文医疗场景的 LLM 评测基准,当前在阿里巴巴天池大赛平台上线进行开放评测。
- LLM 跟踪榜单
An Awesome Collection for LLM in Chinese:已收集超过 100 个中文 LLM 相关的开源模型、应用、数据集及教程。
CLiB 中文大模型能力评测榜单(持续更新):提供分类能力、信息抽取能力、阅读理解能力、表格问答能力等多个维度的大模型评测结果。
寻找那些 ChatGPT/GPT4 开源“平替”们:ChatGPT/GPT4 开源“平替”汇总,包括自主模型、Alpaca 模式微调模型、AGI 项目、榜单、语料等多维度内容。
相关开源项目对比
基于以上调研,项目的选取范围定为:支持本地知识库的 LLM 调用项目。
初步选取符合要求的项目有三个:langchain-ChatGLM:基于本地知识库的 ChatGLM 等大语言模型应用实现、闻达:一个大规模语言模型调用平台、gpt_academic:GPT 学术优化。
模型方面,当前最优 LLM 模型为ChatGLM2-6B,知识库向量化模型选择m3e-base。
langchain-ChatGLM
langchain-ChatGLM 是一个利用langchain思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
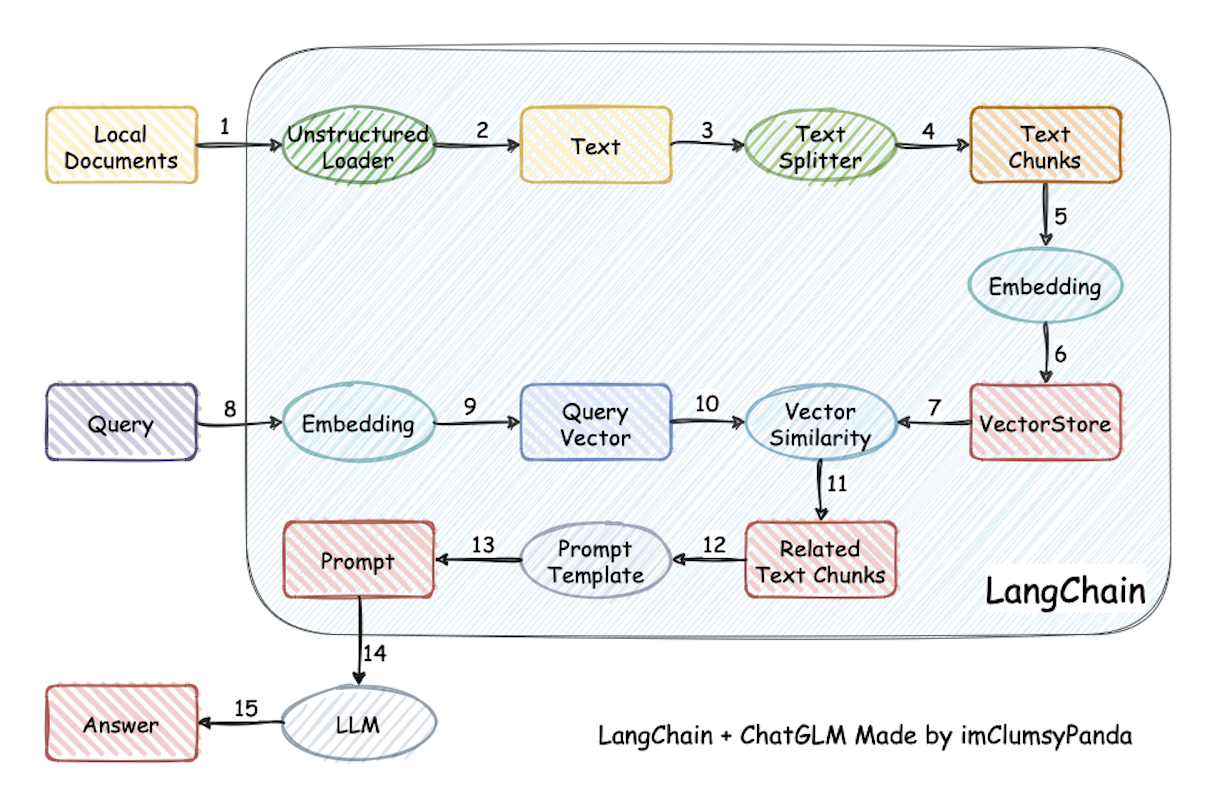
该项目主要特点包括:
支持 Docker 部署,同时提供开发部署方案
支持 ChatGLM、ChatYuan 等多种模型,支持通过 fastchat API 调用任意 LLM
知识库接入非结构化文档,当前已支持 md、pdf、docx、txt 格式,支持 jpg 与 png 格式图片的 OCR 文字识别
路线图(未来计划实现的功能)中包含结构化数据(csv、Excel、SQL 等)接入、知识图谱/图数据库接入、Agent 实现
支持多种知识库 Embedding 模型
支持搜索引擎问答
闻达
闻达项目的设计目标是实现针对特定环境的高效内容生成,同时考虑个人和中小企业的计算资源局限性,以及知识安全和私密性问题。该项目的主要特点包括:
支持 chatGLM-6B\chatGLM2-6B、chatRWKV、llama 系列、openai api 等多种模型接入
支持本地离线向量库(rtst)、本地搜索引擎(fess)、在线搜索引擎三种知识库构建模式
特色 Auto 脚本:通过开发插件形式的 JavaScript 脚本,为平台附件功能,实现包括但不限于自定义对话流程、访问外部 API、在线切换 LoRA 模型
使用宏调用 API 的方式接入 Word 文档
值得一提的是,由社区成员 AlanLee1996 贡献的Wenda-Webui提供了类似 ChatPDF 的文档对话功能。
gpt_academic
gpt_academic 是为 ChatGPT/GLM 设计的图形交互界面,特别优化论文阅读/润色/写作体验,模块化设计,主要特点包括:
支持复旦 MOSS、llama、rwkv、newbing、claude、claude2 等多种模型接入
支持多种模型混合调用,支持模型异步加载
支持 latex 格式论文翻译、总结、润色,支持 latex 公式渲染
支持自定义强大的函数插件,插件支持热更新
丰富的插件库,支持 PDF latex 论文解析、代码工程解释、批量注释生成等多种功能